
Who is this blog for?
This blog is for security leaders who want to learn how to improve web content filtering and protect their organizations from security risks.
Web content filtering is important because it can help to prevent users from accessing malicious or harmful websites. However, traditional web filtering methods often overlook lesser-known websites, which can lead to security risks.
This blog discusses a new approach to web content filtering that uses large language models (LLMs) to train smaller, more efficient models that can classify never-before-seen URLs on the fly. This approach has the potential to revolutionize web content classification and bolster cybersecurity measures.
Read time: 6 minutes
—
While it may not seem as central to security as malware protection and breach detection, web content filtering plays an important role in ensuring regulatory compliance and the safety of workplaces as well as network security. Unlike security classification of URLs, which screens for malicious content such as malware or phishing, web filtering has to label content based not on attack mechanisms but the nature of its content, a much more generalized problem than checking for malicious patterns in the content behind the URL.
Website category labels generally describe what the content or purpose of the site is. Some categories are broad classifications such as “business,” “computers and internet”, “food and dining” and “entertainment”. Others focus on intent, such as “banking,” “shopping,” “search engines,” “social media,” “job search” and “education”. And then there are categories that may include content of concern – “sexually explicit,” “alcohol,” “marijuana” and “weapons,” for example. Organizations may want to set various policies for filtering or measuring the types of websites accessed from their networks.
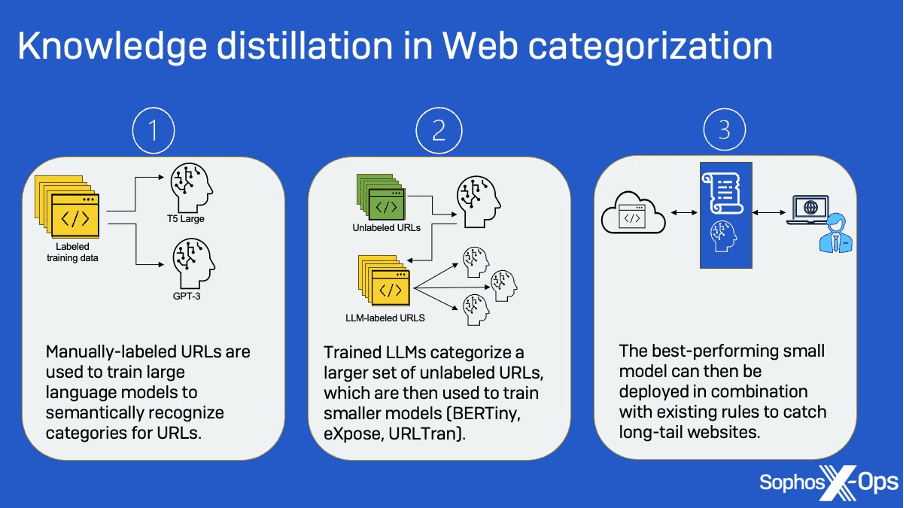
Sophos X-Ops has been researching ways to apply large language model (LLM) machine learning to web filtering to help catch the “long tail” of websites – those millions of domains that have relatively few visitors and little or no visibility to human analysts. LLMs themselves are not practical for this application because of their size and computational resource cost. But they can be used in turn as “teacher” models to train smaller models on categorization – reducing the computational resources required to generate labels on the fly for newly encountered domains.
Using LLMs such as OpenAI’s GPT-3 and Google’s T5 Large, the SophosAI team were able to train much smaller models to classify never-before-screened URLs on the fly. Most importantly, the methodology used here could be used to create small, economically deployable models based on the output of LLMs for other security tasks.
The team’s research, detailed in a recently published paper entitled “Web Content Filtering Through Knowledge Distillation of Large Language Models,” explores ways in which LLMs can be used to bolster existing human-driven site classification, and to build systems that can be deployed to perform real-time labelling of never-before-seen URLs.
The “long tail” problem
Categorization of sites has relied largely on rule-based domain-to-category mapping, where analyst-crafted signatures are used to look for tell-tales in URLs to quickly assign labels to new domains. This sort of mapping is vital in speedy labelling of URLs on well-known sites and preventing false positives that block important content. The hands-on human identification of site classification patterns gets folded back into the domain mapping tools’ feature sets.
The problem comes with the “long tail” of websites—those less-visited domains that typically don’t get signatures assigned to them. With the daily emergence of thousands of new websites, and with over a billion existing websites, maintaining and scaling signature-based approaches manually for the long tail has become increasingly challenging. That’s evident in the steep drop-off of labelling for less-visited domains – while well-known, high-traffic sites get nearly 100 percent coverage in most labelling schemes, as shown in the diagram below, the proportion of analyst-labelled domains begins to fall off quickly beyond the top hundred visited domains. Sites ranked below the top 5000 are less than 50 percent likely to have been labelled for content.
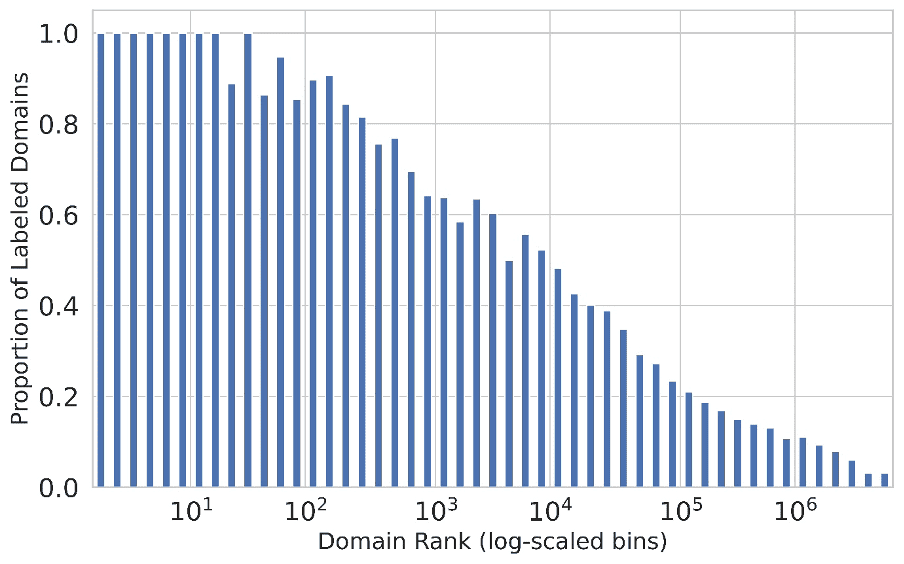
Figure 1. Labelling of content relative to popularity of domains, derived from telemetry. One way to fix this is through application of machine learning for processing previously unlabelled domains. But up until now, most machine learning efforts (such as Microsoft’s URLTran) have used deep learning models to focus on the task of detecting security threats, rather than categorizing sites by content. These models could be retrained to perform multi-category classification, but they would require extremely large training sets of data. URLTran used over 1 million samples just for training on detection of malicious URLS.
Automating with AI
That’s where LLMs come in. Because they are pre-trained on massive amounts of unlabelled text, the SophosAI team believed that LLMs could be used to perform URL labelling more accurately and with much fewer initial data. When fine-tuned on data labelled with domain-propagation signatures, the SophosAI team found that LLMs have a 9% accuracy advantage over the state-of-the-art model architecture from Microsoft when tackling the “long tail” categorization problem – and only required a training set of thousands of URLs, rather than millions.
The LLMs, using semantic relationships between the site classes and keywords within URLs in a smaller data set, were then used to create labels for an unlabelled set of data from long tail sites that were in turn used to train smaller models (the BERTiny and BERT-based URLTran transformer models and the 1D convolutional model eXpose). This “knowledge distillation” approach allowed the team to reach performance levels similar to that of the LLM with models 175 times smaller, reducing the number of parameters from 770 million to just 4 million.
While the most accurate sets of models created performed far better than models trained via “deep learning” alone, their accuracy fell short of perfection – even the best models scored under 50 percent accuracy. Many URLs failed to be properly labelled simply because they didn’t have sufficient “signals” embedded in them, while others had keywords that could be associated with multiple classifications – creating uncertainty that could only be clarified by deeper examination of the content behind the URL.
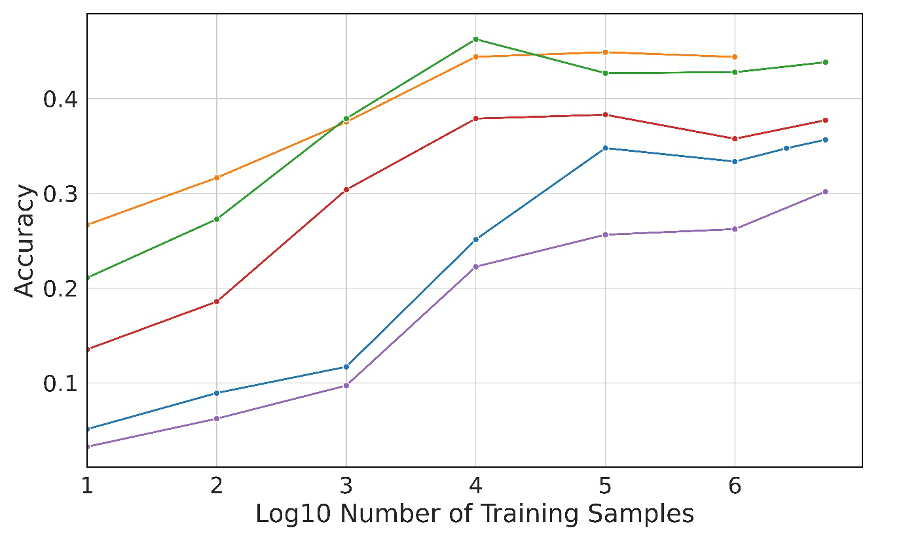
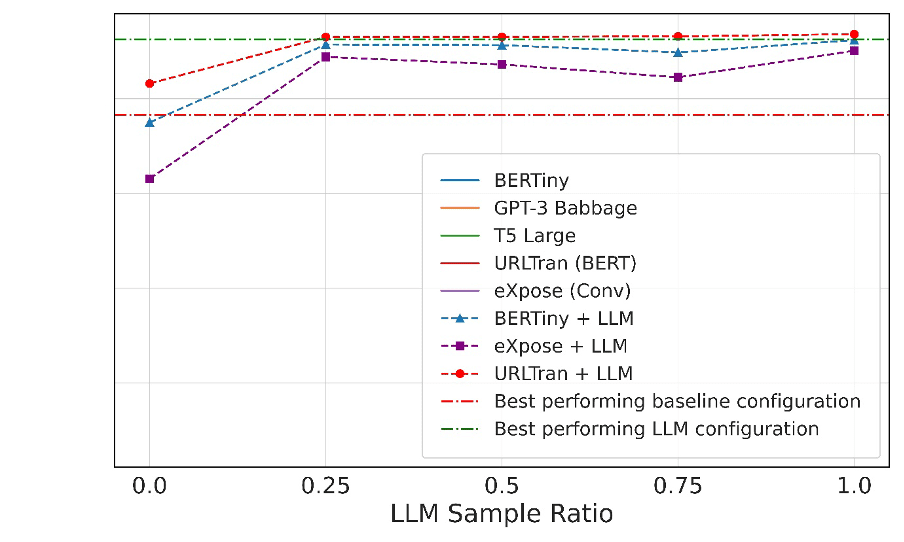
Figures 3 and 4. An accuracy plot of trained models. LLMs outperformed smaller models trained with deep learning, but the smaller models approached the same level of accuracy when the LLMs were used as teaching models. (Y axis in both charts are from 0 to 0.5 accuracy.)
However, the T5 Large model performed reasonably well on categories that would potentially be filtered out, as shown in the confusion matrix below – with gambling and peer-to-peer sharing sites having near-perfect labelling on test data. Alcohol, weapons, and pornography sites also had better than 60% true positive detection rates.
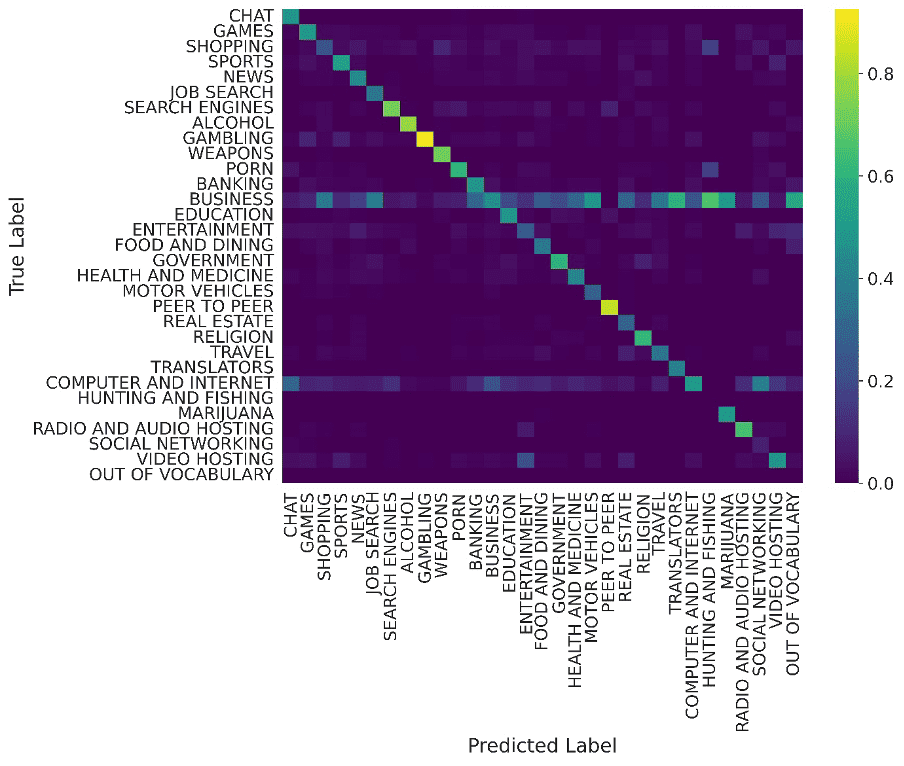
Figure 5. A confusion matrix showing the relationship between the labels the T5 Large model assigned to test URLs, and their true manually assigned labels.
There are several ways to improve this accuracy going forward that the SophosAI team has suggested. First, allowing for the assignment of multiple categories to a site would eliminate problems with category overlap. Augmenting the URL samples with retrieved HTML and images from them could also provide better recognition of their categorization, and newer LLMs, such as GPT-4, could be used as a teacher.
When combined with existing processes, this form of AI-based classification can greatly improve the handling of long tail websites. And there are other security-related tasks that the “knowledge distillation” methodology tested in this experiment could be applied to.
“Conventional web indexing methods often overlook lesser-known websites, leading to potential risks as malicious or harmful content can go undetected. Utilising large language models, which can better comprehend contextual cues and language nuances, will revolutionise web content classification and bolster cybersecurity measures by providing a comprehensive understanding of the vast uncharted web” concludes Babble spokesperson.
This blog was written and shared by Sophos and originally published on their website on 22 June 2023.



